JSON
概念
JSON 是一种轻量级的数据交换格式。
理解
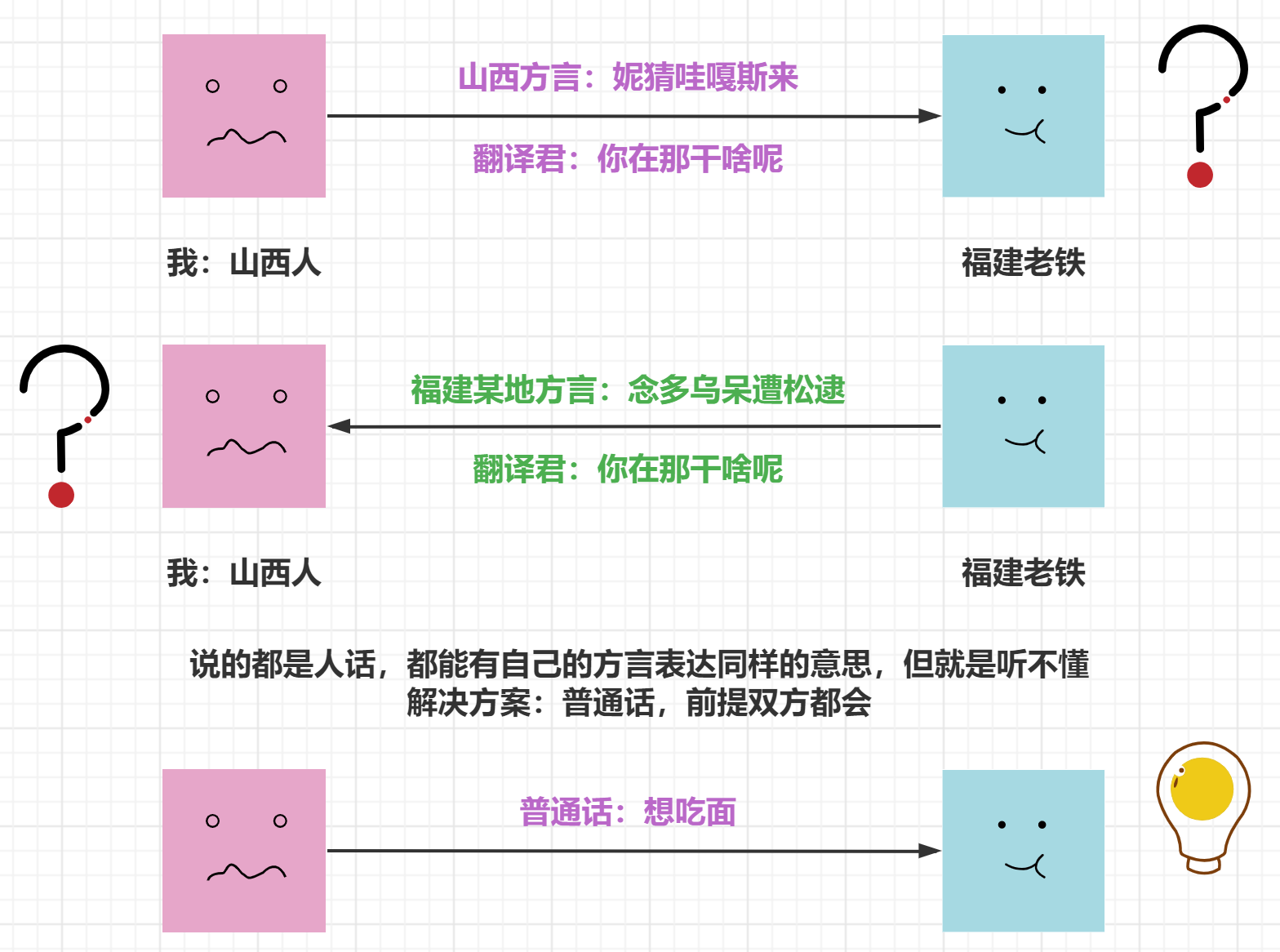
数据交换格式那么多,为啥还要学个 JSON?
![image-20210919172932733]()
数据交换格式是不同平台、语言中进行数据传递的通用格式。比如 Python 和 Java 之间要对话,你直接传递给 Java 一个 dict 或 list 吗?Java 会问,这是什么鬼?虽然它也有字典和列表数据类型,但两种字典不是一个“物种”,根本无法相互理解。这个时候就需要用 Json 这种交换格式了,Python 和 Java 都能理解 Json。那么别的语言为什么能理解 Json 呢?因为这些语言都内置或提供了 Json 处理模块,比如 Python 的 json 模块。
基本用法
JSON格式: 在各种语言中,都可以被读取,被用作不同语言的中间转换语言【类似翻译器】
主要结构
- “键/值” 对的集合;python 中主要对应 字典
- 值的有序列表;在大部分语言中,它被理解为 数组
| Python |
JSON |
| dict |
object |
| list, tuple |
array |
| str |
string |
| int, float |
number |
| True |
true |
| False |
false |
| None |
null |
常用函数
- loads 方法:对编码后的 json 对象进行 decode 解密,得到原始数据,需要使用的 json.loads() 函数
- dumps 方法:可以将原始数据转换为 json 格式
案例
1
2
3
4
5
6
7
8
9
| [root@localhost xxx]
>>> import json
>>> adict = {'user': 'tom', 'age': 20}
>>> data = json.dumps(adict)
>>> data
>>> type(data)
>>> jdata = json.loads(data)
>>> jdata
>>> type(jdata)
|
requests 模块
requests 简介
- requests 是用 Python 语言编写的、优雅而简单的 HTTP 库
- requests 内部采用来 urillib3
- requests 使用起来肯定会比 urillib3 更简单便捷
- requests 需要单独安装
GET 和 POST
- 通过 requests 发送一个 GET 请求,需要在 URL 里请求的参数可通过 params 传递
- 与 GET 不同的是,POST 请求新增了一个可选参数 data,需要通过 POST 请求传递 body 里的数据可以通过 data 传递
requests 发送 GET 请求
案例 1:处理文本数据
1
2
3
4
5
6
7
| [root@localhost xxx]
[root@localhost xxx]
>>> import requests
>>> url = 'http://www.163.com'
>>> r = requests.get(url)
>>> r.text
|
案例 2:处理图片视频音频等数据
1
2
3
4
5
6
| >>> url2 = 'http://pic1.win4000.com/wallpaper/6/58f065330709a.jpg'
>>> r2 = requests.get(url2)
>>> r2.content
>>> with open('/tmp/aaa.jpg', 'wb') as fobj:
... fobj.write(r2.content)
[root@localhost xxx]
|
练习:下载新浪首页图片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| import re,os,requests
def download(url, fname):
with open(fname, mode="wb") as fw:
fw.write(requests.get(url).content)
def get_url(fname, patt):
result = []
patt_obj = re.compile(patt)
with open(fname, mode="r") as fr:
for item in fr.readlines():
data = patt_obj.search(item)
if data != None:
result.append(data.group())
return result
if __name__ == '__main__':
if os.path.exists("/opt/myweb.html") == False:
download("https://www.sina.com.cn/", "/opt/myweb.html")
if os.path.exists("/tmp/images") == False:
os.mkdir("/tmp/images")
pic_patt = "(http|https)://[\w\./-]+\.(jpg|jpeg|png)"
res_list = get_url("/opt/myweb.html", pic_patt)
for item in res_list:
download(item, "/tmp/images/"+os.path.basename(item))
|
案例 3:处理 json 格式的数据
天气预报查询
- 搜索 中国天气网 城市代码查询, 查询城市代码
- 城市天气情况接口
- 实况天气获取: http://www.weather.com.cn/data/sk/城市代码.html
1
2
3
4
5
6
7
| >>> url3 = 'http://www.weather.com.cn/data/sk/101130101.html'
>>> r3 = requests.get(url3)
>>> r3.json()
>>> r3.encoding
'ISO-8859-1'
>>> r3.encoding = 'utf8'
>>> r3.json()
|
设定头部
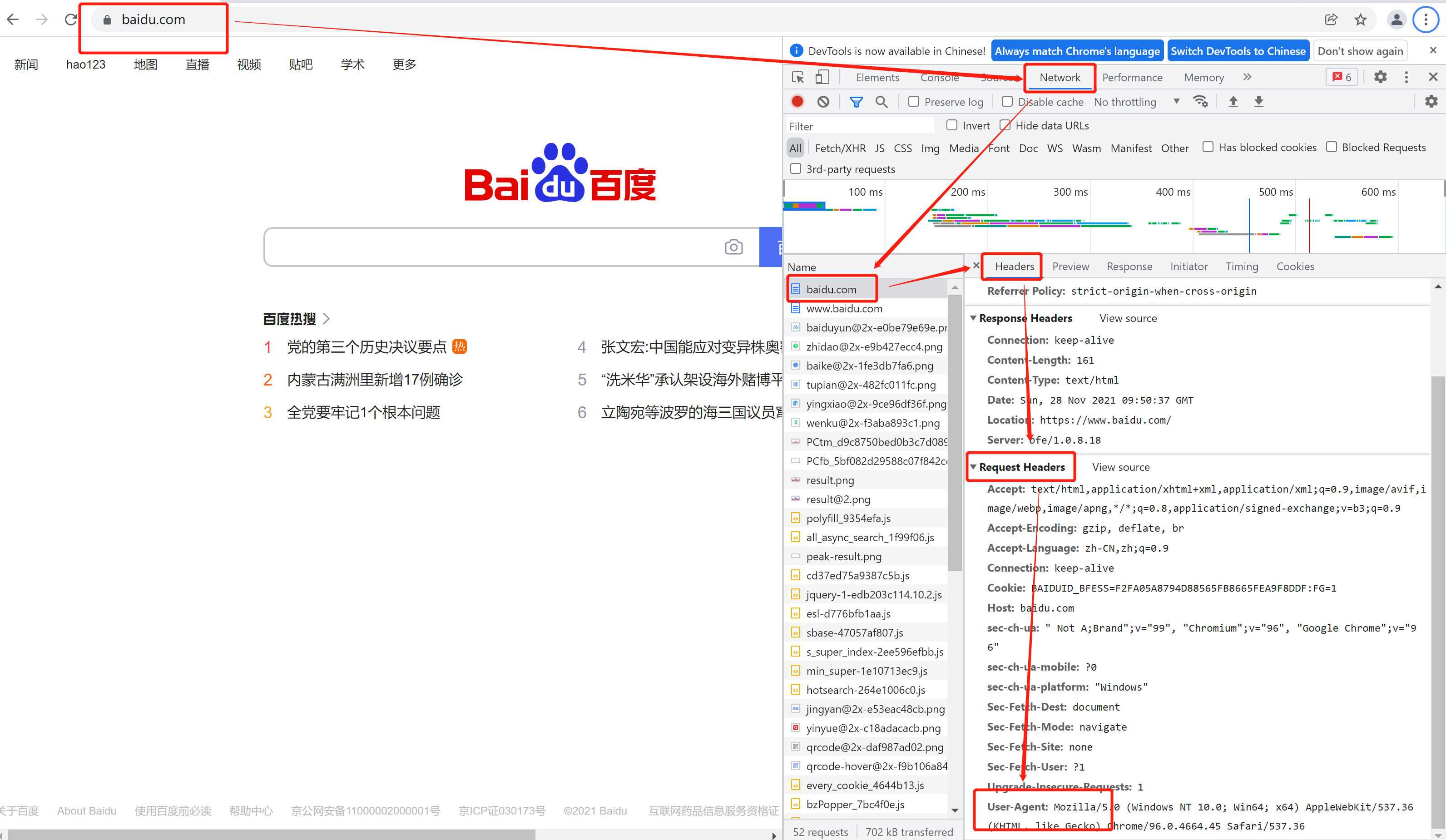
- 用户也可以自己设定请求头
- 获取网站的【User-Agent】请求头信息
![image-20211128175135797]()
1
2
3
4
5
6
7
|
[root@localhost xxx]
>>> js_url = 'http://www.jianshu.com'
>>> headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'}
>>> r = requests.get(js_url, headers=headers)
>>> r.text
|
请求参数
- 当访问一个 URL 时,我们经常需要发送一些查询的字段作为过滤信息,例如:httpbin.com/get?key=val,这里的 key=val 就是限定返回条件的参数键值对
- 当利用 python 的 requests 去发送一个需要包含这些参数键值对时,可以将它们传给params
1
2
3
4
5
6
7
8
9
10
11
12
| import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
url = 'https://www.baidu.com/s?'
kw = {'wd': 'python'}
response = requests.get(url, headers=headers, params=kw)
print(response.text)
|
pickle 模块
模块简介
- 把数据写入文件时,常规的文件方法只能把字符串对象写入。其他数据需先转换成字符串再写入文件
- python 提供了一个标准的模块,称为 pickle。使用它可以在一个文件中 存储任何 python 对象,之后又可以把它完整无缺地取出来
主要方法
| 方法 |
功能 |
| pickle.dump(obj, file) |
将 Python 数据转换并保存到 pickle 格式的文件内 |
| pickle.load(file) |
从 pickle 格式的文件中读取数据并转换为 python 的类型 |
基本使用
- 常规方法写入数据,只能是字符串类型,其他类型无法写入,例如:int,字典,列表等类型;
- pickle模块,可以在文件中存储任何类型的数据,也可以完整取出任何类型的数据;
pickle 模块方法
1
2
3
4
5
6
7
8
| >>> f = open('/tmp/a.data', mode='wb')
>>> user = {'name': 'tom', 'age': 20}
>>> import pickle
>>> pickle.dump(user,f)
>>> f.close()
>>> f = open('/tmp/a.data', mode='rb')
>>> adict = pickle.load(f)
>>> adict
|
案例:修改登录注册程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| import pickle
import os
def write_dict():
if os.path.exists("/tmp/user.data") == False:
userdb = {}
fw = open("/tmp/user.data", mode="wb")
pickle.dump(userdb, fw)
fw.close()
def register():
username = input("username:")
fr = open("/tmp/user.data", mode="rb")
user = pickle.load(fr)
fr.close()
if username in user.keys():
print("用户名已存在")
else:
password = input("password: ")
user[username] = password
fw = open("/tmp/user.data", mode="wb")
pickle.dump(user, fw)
fw.close()
def login():
username = input("username:")
password = input("password:")
fr = open("/tmp/user.data", mode="rb")
user = pickle.load(fr)
fr.close()
if user.get(username) != password:
print("登陆失败")
else:
print("登陆成功")
def show_menu():
write_dict()
while True:
choice = input("1.register 2.login 3.退出 Please enter choice(1/2/3): ")
if choice not in ["1", "2", "3"]:
print("请正确输入(1/2/3)!!!!")
continue
elif choice == "3":
print("Byebye~")
break
elif choice == "1":
register()
else:
login()
if __name__ == '__main__':
show_menu()
|
模块练习
练习:创建系统用户
需求
- 编写一个程序(函数),实现创建用户的功能
- 提示用户输入 用户名
- 随机生成 8位密码 (导入之前的模块文件)
- 创建用户并设置密码
- 将用户相关信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import randpass2
import subprocess
def adduser(user, passwd, fname):
result = subprocess.run('id %s &> /dev/null' % user, shell=True)
if result.returncode == 0:
print('%s已存在' % user)
else:
subprocess.run('useradd %s' % user, shell=True)
subprocess.run('echo %s | passwd --stdin %s' % (passwd, user), shell=True)
info = """用户信息:
用户名:%s
密码:%s
""" % (user, passwd)
with open(fname, 'a') as fobj:
fobj.write(info)
if __name__ == '__main__':
passwd = randpass2.randpass()
adduser("zhangsan", passwd, '/tmp/users.txt')
|