模块基础
定义模块
基本概念
- 模块是从逻辑上组织python代码的形式
- 当代码量变得相当大的时候,最好把代码分成一些有组织的代码段,前提是保证它们的 彼此交互
- 这些代码片段相互间有一定的联系,可能是一个包含数据成员和方法的类,也可能是一组相关但彼此独立的操作函数
- 人话:一个 .py文件 就是一个python模块
导入模块 (import)
- 使用 import 导入模块
- 模块属性通过 “模块名.属性” 的方式调用
- 模块函数通过 “模块名.函数名” 的方式调用
- 如果仅需要模块中的某些属性,也可以单独导入
为什么需要导入模块?
可以提升开发效率,简化代码
图例
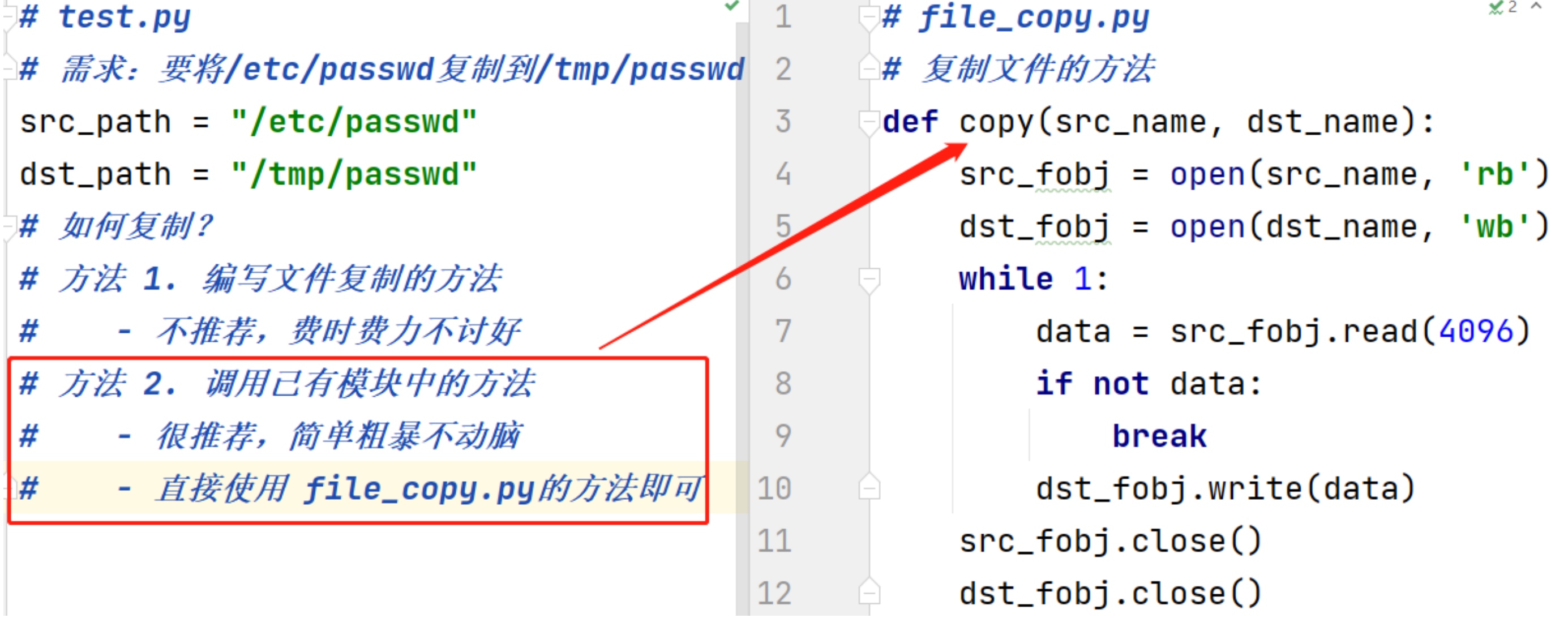
正确使用
1 | # test.py,将 file_copy.py 放在同级目录下 |
常用的导入模块的方法
- 一行指导入一个模块,可以导入多行, 例如:import random
- 也可一行导入多个模块,例如:import random, sys
- 只导入模块中的某些方法,例如:from random import choice, randint
模块加载 (load)
- 一个模块只被 加载一次,无论它被导入多少次
- 只加载一次可以 阻止多重导入时,代码被多次执行
- 如果两个文件相互导入,防止了无限的相互加载
- 模块加载时,顶层代码会自动执行,所以只将函数放入模块的顶层是最好的编程习惯
模块特性及案例
模块特性
模块在被导入时,会先完整的执行一次模块中的 所有程序
案例
1 | # foo.py |
结果:
1 | # foo.py -> __main__ 当模块文件直接执行时,__name__的值为‘__main__’ |
所以我们以后在 Python 模块中执行代码的标准格式:
1 | def test(): |
练习:生成随机密码
创建 randpass.py 脚本,要求如下:
- 编写一个能生成 8 位随机密码的程序
- 使用 random 的 choice 函数随机取出字符(大小写字母数字)
- 改进程序,用户可以自己决定生成多少位的密码
版本一:
1 | import random # 调用随机数模块random |
版本二(优化):函数化程序,并可以指定密码长度,在randpass.py文件中操作
1 | import random # 调用随机数模块random |
版本三:随机密码的字符选择可以调用模块
1 | # 调用随机数模块random |
时间模块
time 模块
时间表示方式
- 时间戳 timestamp:表示的是从 1970 年1月1日 00:00:00 开始按秒计算的偏移量
- UTC(Coordinated Universal Time, 世界协调时)亦即格林威治天文时间,世界标准时间。在中国为 UTC+8 DST(Daylight Saving Time) 即夏令时;
- 结构化时间(struct_time): 由 9 个元素组成
结构化时间(struct_time)
使用 time.localtime() 等方法可以获得一个结构化时间
1 | import time |
结构化时间共有9个元素,按顺序排列如下表:
| 索引 | 属性 | 取值范围 |
|---|---|---|
| 0 | tm_year(年) | 比如 2021 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 59 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一,6表示周日) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为-1 |
然结构化时间是一个序列,那么就可以通过索引进行取值,也可以进行分片,或者通过属性名获取对应的值。
1 | import time |
注意
但是要记住,Python的time类型是不可变类型,所有的时间值都只读,不能改
1 | t.tm_mon = 2 |
格式化时间字符串
利用 time.strftime('%Y-%m-%d %H:%M:%S') 等方法可以获得一个格式化时间字符串
1 | import time |
注意其中的空格、短横线和冒号都是美观修饰符号,真正起控制作用的是百分符
对于格式化控制字符串 "%Y-%m-%d %H:%M:%S,其中每一个字母所代表的意思如下表所示,注意大小写的区别:
| 格式 | 含义 | 格式 | 含义 |
|---|---|---|---|
| %a | 本地简化星期名称 | %m | 月份(01 - 12) |
| %A | 本地完整星期名称 | %M | 分钟数(00 - 59) |
| %b | 本地简化月份名称 | %p | 本地am或者pm的相应符 |
| %B | 本地完整月份名称 | %S | 秒(01 - 59) |
| %c | 本地相应的日期和时间 | %U | 一年中的星期数(00 – 53,星期日是一个星期的开始) |
| %d | 一个月中的第几天(01 - 31) | %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %H | 一天中的第几个小时(24小时制,00 - 23) | %x | 本地相应日期 |
| %I | 第几个小时(12小时制,01 - 12) | %X | 本地相应时间 |
| %j | 一年中的第几天(001 - 366) | %y | 去掉世纪的年份(00 - 99) |
| %Z | 时区的名字 | %Y | 完整的年份 |
time 模块主要方法
1. time.sleep(t)
time 模块最常用的方法之一,用来睡眠或者暂停程序t秒,t可以是浮点数或整数。
1 | import time |
2. time.time()
返回当前系统时间戳。时间戳可以做算术运算。
1 | import time |
3. time.gmtime([secs])
将一个时间戳转换为 UTC时区的结构化时间。可选参数secs的默认值为 time.time()。
1 | import time |
4. time.localtime([secs])
将一个时间戳转换为 当前时区 的结构化时间。如果secs参数未提供,则以当前时间为准,即time.time()。
1 | import time |
5. time.mktime(t)
结构化时间转换为时间戳,t(结构化时间)
1 | import time |
6. time.strftime(format [, t])
返回格式化字符串表示的当地时间。把一个struct_time(如time.localtime()和time.gmtime()的返回值)转化为格式化的时间字符串,显示的格式由参数format决定。如果未指定t,默认传入time.localtime()。
1 | import time |
7. time.strptime(string[,format])
将格式化时间字符串转化成结构化时间
- 该方法是
time.strftime()方法的逆操作。 time.strptime()方法根据指定的格式把一个时间字符串解析为结构化时间。- 提供的字符串要和 format参数 的格式一一对应
- 如果string中日期间使用 “-” 分隔,format中也必须使用“-”分隔
- 时间中使用冒号 “:” 分隔,后面也必须使用冒号分隔
- 并且值也要在合法的区间范围内
1 | import time |
时间格式之间的转换
Python的三种类型时间格式,可以互相进行转换
| 从 | 到 | 方法 |
|---|---|---|
| 时间戳 | UTC结构化时间 | gmtime() |
| 时间戳 | 本地结构化时间 | localtime() |
| 本地结构化时间 | 时间戳 | mktime() |
| 结构化时间 | 格式化字符串 | strftime() |
| 格式化字符串 | 结构化时间 | strptime() |
练习:取出指定时间段的日志
需求
有一日志文件,按时间先后顺序记录日志
给定 时间范围,取出该范围内的日志
自定义日志文件 myweb.log
1
2
3
4
5
6
7[root@localhost ~]# vim /opt/myweb.log
2030-01-02 08:01:43 aaaaaaaaaaaaaaaaa
2030-01-02 08:34:23 bbbbbbbbbbbbbbbbbbbb
2030-01-02 09:23:12 ccccccccccccccccccccc
2030-01-02 10:56:13 ddddddddddddddddddddddddddd
2030-01-02 11:38:19 eeeeeeeeeeeeeeee
2030-01-02 12:02:28 ffffffffffffffff【方案一】
1 | # 取出指定时间段 [9点~12点] 的行 |
【方案二】
1 | # 日志文件中,时间点是从前往后不断增加的,所以只要遍历到有一行时间超过预计,则后面的所有行均是不满足条件的 |
python 语法风格和模块布局
变量赋值
1. python支持链式多重赋值
1 | x = y = 10 # 将10赋值给x和y |
2. 给列表使用多重赋值时,两个列表同时指向同一个列表空间,任何一个列表改变,另外一个随着改变
1 | alist = blist = [1, 2] |
3. python 的多元赋值方法
1 | a, b = 10, 20 # 将10和20, 分别赋值给a和b |
4. 在python中,完成两个变量值的互换
1 | a, b = 100, 200 # 将100和200,分别赋值给变量a和变量b |
合法标识符
- Python 标识符,字符串规则和其他大部分用 C 编写的高级语言相似
- 第一个字符必须是 字母或下划线 _
- 剩下的字符可以是字母和数字或下划线
- 大小写敏感
关键字
- 和其他的高级语言一样,python 也拥有一些被称作关键字的保留字符
- 任何语言的关键字应该保持相对的稳定,但是因为 python 是一门不断成长和进化的语言,其关键字偶尔会更新
- 关键字列表和 iskeyword() 函数都放入了 keyword 模块以便查阅
案例:查看,判断python中的关键字
1 | import keyword # 导入模块keyword |
内建
- Python 为什么可以直接使用一些内建函数,而不用显式的导入它们?
- 比如 str()、int()、id()、type(),len() 等,许多许多非常好用,快捷方便的函数。
- 这些函数都是一个叫做
builtins模块中定义的函数,而builtins模块默认 在Python环境启动的时候就自动导入,所以可以直接使用这些函数
字符串
格式化详解
- 百分号:可以使用格式化符号来表示特定含义
| 格式化字符 | 转换方式 |
|---|---|
| %s | 优先用str()函数进行字符串转换 |
- f 字符串:是 Python3.6 之后加入的标准库
1 | name, age, list01 = "benben", 25, [1, 2] |
注意
- 可以传入任意类型的数据,如 整数、浮点数、列表、元组甚至字典,都会自动转成字符串类型
字符串函数
1 | s1 = "hello world" |